Longterm Storage
The GRAX app is built for longterm, near-infinite retention of your Salesforce object data. To facilitate fast, reliable, and scalable storage of this data, GRAX uses AWS S3 and recommends comparable options across Azure and GCP. To understand more about how GRAX uses this storage, storage growth expectations, why we don't recommend cross-cloud usage, and supported lifecycle processes, see the sections below.
Supported Cloud Blob-Storage Platforms
- AWS S3
- Azure Blob Storage
- GCP Cloud Storage
Supported Storage Types
On AWS, GRAX only supports the standard storage class. GRAX won't work with Intelligent Tiers, Glacier, or Outposts.
On Azure, GRAX only supports the standard (GPv2) storage account tier. Premium storage accounts or containers won't work with GRAX.
On GCP, GRAX only supports standard storage. Nearline, Coldline, or Archive storage plans/containers won't work with GRAX.
Unsupported Activities
Direct access, modification, or removal of data from the GRAX bucket isn't supported. Attempts to rename, remove, or modify blobs within the storage bucket cause data loss and GRAX availability issues. GRAX isn't responsible for partial or complete loss of your backup dataset if this restriction is violated.
In conjunction with the above, we also don't support the following:
- Lifecycle rules triggering blob deletion
- Lifecycle rules moving blobs to alternative storage tiers/classes
- Restoration via blob versioning
For targeted record deletion (like GDPR compliance), see our related documentation.
Required Permissions
AWS S3 Permissions
At a minimum, GRAX requires the s3:ListBucket, s3:GetObject, s3:PutObject, and s3:DeleteObject permissions on the bucket. If you're using KMS encryption, GRAX also requires the kms:DescribeKey, kms:Decrypt, kms:Encrypt, kms:GenerateDataKey, and kms:ReEncrypt* permissions on the KMS key resource.
Azure Blob Storage Permissions
GRAX only supports Storage Account Access Keys for Azure Blob Storage. As such, granular permissions aren't currently available.
How GRAX Stores Your Data
GRAX's primary storage layer consists of compressed blobs in a proprietary format. Based on leading big-data storage practices, our storage layer provides write-optimized and scalable performance useful for data backup.
To facilitate this write-optimized performance, GRAX initially writes data with minimal compression and de-duplication. That data is then processed asynchronously to compress, de-duplicate, and sort the contained records over the hours following initial backup. We'll call this "compaction." This process is transparent to the GRAX user, as access to the data isn't limited during this process.
Compaction produces immutable storage blobs. As data is compacted past the original written state, new blobs are written to represent that data and the source blobs are marked for deletion. 14 days after being marked as such, those non-compacted blobs are deleted from storage as the data within them is represented elsewhere in "better" blobs. This process repeats as your dataset grows, meaning that compaction is a permanent and recurring background process that maintains your dataset.
Also for consideration, the vast majority of load on the GRAX app occurs in the first few weeks of operation in which you connect GRAX and we capture a snapshot of the entire exposed Salesforce dataset. This means that data can build up temporarily until compaction and then deletion catches up.
With the above process in consideration, we can plot the expected data storage usage on a generalized curve (specific values, units, and time frames depend on your environment):
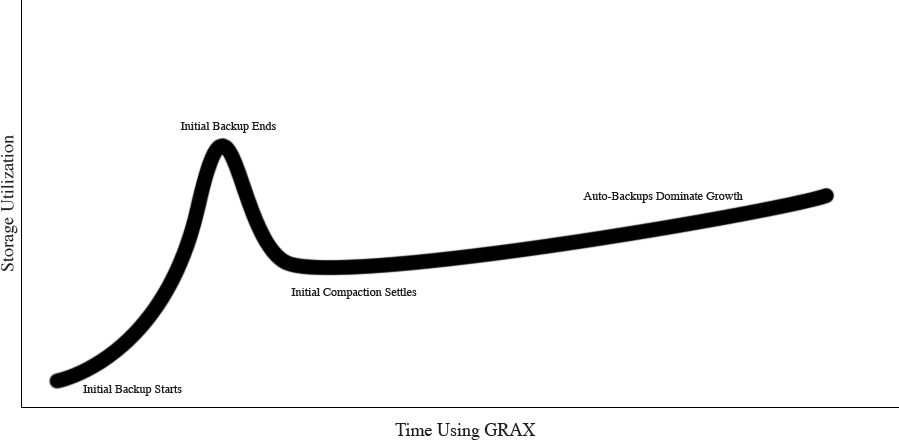
How Much GRAX Storage Costs
Data stored in GRAX takes up significantly less space than the same data would take up in Salesforce. Cloud storage is also vastly cheaper than Salesforce storage; most users hardly notice the cost of data-at-rest in a GRAX environment. Here are some breakdowns of real-world costs of data-at-rest in AWS S3.
NOTE: calculations below don't include file/binary storage consumed by Attachments, ContentDocuments, or EventLogFiles. Storage Usage for those binary components can currently be assumed to be 1:1 with Salesforce and cost-estimated with published storage rates.
ALSO NOTE: calculations below only consider data-at-rest rates. All cloud providers bill for data-transfer or data-access operations. Those are considered variable costs based on usage of GRAX features and overall processing load. Our published AWS estimate contains estimates for GET, LIST, PUT, and DELETE requests as well as overall data-transfer expectations.
- Average Case:
- Production environments, on average, consume a low amount of storage
- 216 GB consumed by average environment
- $4.97 per month at standard S3 data-at-rest rates
- High Estimate:
- Published cost estimates contain a very high recommended S3 cap to allow for longterm growth
- 5 TB total storage space recommendation
- $117 per month at standard S3 data-at-rest rates
- Largest:
- International support organization with high record turnover rate
- 3+ year relationship with consistent full-org backups
- 6,000,000,000+ record versions backed up with GRAX
- 6 TB of total storage consumed
- $141 per month at standard S3 data-at-rest rates
More Information
For information on how to connect your GRAX app to a bucket for the first time (or change your existing storage connection), review our related documentation.
Updated 9 days ago