History Stream
GRAX History Stream lets you drive any type of downstream consumption of backed up or archived data with your GRAX dataset. By designating a set of objects for automated continuous export to Parquet format, you can create a valuable data source for applications like AWS Glue and further data analytics tools.
With History Stream you can take control of your historical data, and do more with it throughout your enterprise. Whether you're looking to load data into a central warehouse, or feed an analytics platform such as Tableau, AWS QuickSight or PowerBI the History Stream facilitates easy data movement with minimal configuration and setup.
What's more is that you access to your entire historical data set, not just the latest version.
How It Works
Once enabled, History Stream continuously monitors the GRAX Vault for new data. When it finds data, and it's safe to write, it is written to parquet format as detailed below. Every backed up version of a record for an enabled object is included.
Data Structure
As is the case for backup data, the History Stream writes parquet files to your configured object store, typically AWS S3 or Azure Blob Storage.
In modern object stores, we can use object key naming schemes to take advantage of the massive read/write scalability of these services. Furthermore, many of the data lake applications that would typically be employed in ingesting and processing History Stream data supports common naming conventions to assist with efficiently recognizing and ingesting new data. With these two considerations in mind, we structure our History Stream data as follows:
parquet/org=1234/object=myObject/day=nn/hour=nn
parquetis the top level directory present in the object storage bucket. All History Stream data goes here. You don't need to create this "folder," it is created automatically.orgrepresents the unique ID of your Salesforce orgobjectis the name of your enabled object. If you have multiple objects configured for History Stream, you can see a directory for each in here.dayis the day the data was written to the GRAX Vault. Depending on your backup job configuration, you may not have data for every day. You'll see a directory for each day where data was backed up.houris the hour data was written to the GRAX vault. If you have hourly backups enabled, you might see as many as 24 directories in here.
NOTE
Times are in UTC
Configuring Objects
For an object to be included in the History Stream, you have to explicitly turn it on. Any object that's supported for backup works.
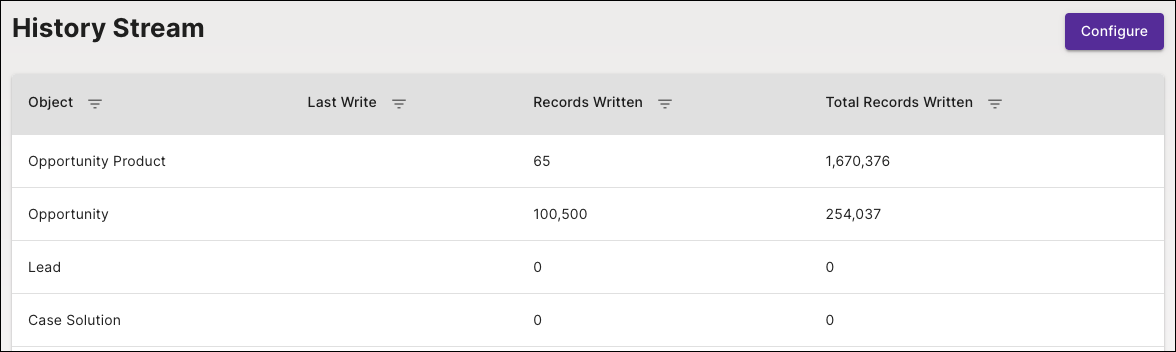
With the new GRAX Webapp, the History Stream tab provides the ability to:
- Enable objects for History Stream
- View which objects have been enabled
- View their
last writetime. This is the most recent time that new data for the specific objects was found in the GRAX data vault and written to the history stream parquet directories - See metrics for the number of records written in the last write and all time
Verify That It's Working
Once configured for one or more objects, History Stream process automatically starts running every 5 minutes. Here's what to expect and how to verify that it's working:
- After the first run, that is 5-10 minutes after the feature was turned on, run you should see the
parquetdirectory created in your object storage bucket. It may take some time for object data to show up. See below for an explanation of what to expect.
When To Expect Data
As mentioned, we partition data by hour. Once the History Stream has written data for a particular hour for a specific object it sets an internal watermark to keep track of where to start from on the next run.
So, if we just wrote data for hour=20 on a given day, the next run is going to start looking for data that was written in hour=21. Thus, when we write data for hour=20, we have to make sure no additional data can come in for this hour. Otherwise we might miss data on the next run. Currently, we accomplish this by writing data for a given hour 15 minutes after the hour.
How long does it take for Parquet data to appear?
It may take two hours for your first data to appear in the History Stream
Conducting a Basic Data Check
Once you've got everything set up, it's always nice to conduct a basic check to see that everything is as expected before configuring any downstream integrations etc. Here are a couple of ways to do that:
Downloading and Checking a Parquet file from S3
- Log in to the AWS Console
- Navigate to the bucket you have configured for GRAX
- Traverse the History Stream directory hierarchy, and locate an hourly partition with data in it. You'll see a file named something like
data-00000.parquet - From "Object Actions" menu, select "Download"
Once the file is downloaded to your computer, you can use a command-line utility such as parquet-tools to print its contents:
% parquet-tools cat data-00000.parquet
Title = Senior Editor
LastName = Iiannone
Id = 0035e000001uC6AAAU
SystemModstamp = 2021-04-30T20:14:14.000Z
FirstName = Jobyna
IsDeleted = false
OwnerId = 0055e000001D8WEAA0
PhotoUrl = /services/images/photo/0035e000001uC6AAAU
LastModifiedDate = 2021-04-30T20:14:14.000Z
IsEmailBounced = false
Name = Jobyna Iiannone
AccountId = 0015e0000043cIcAAI
CleanStatus = Pending
CreatedDate = 2021-04-30T20:14:14.000Z
LastModifiedById = 0055e000001D8WEAA0
CreatedById = 0055e000001D8WEAA0
Email = [email protected]
Using S3 Select
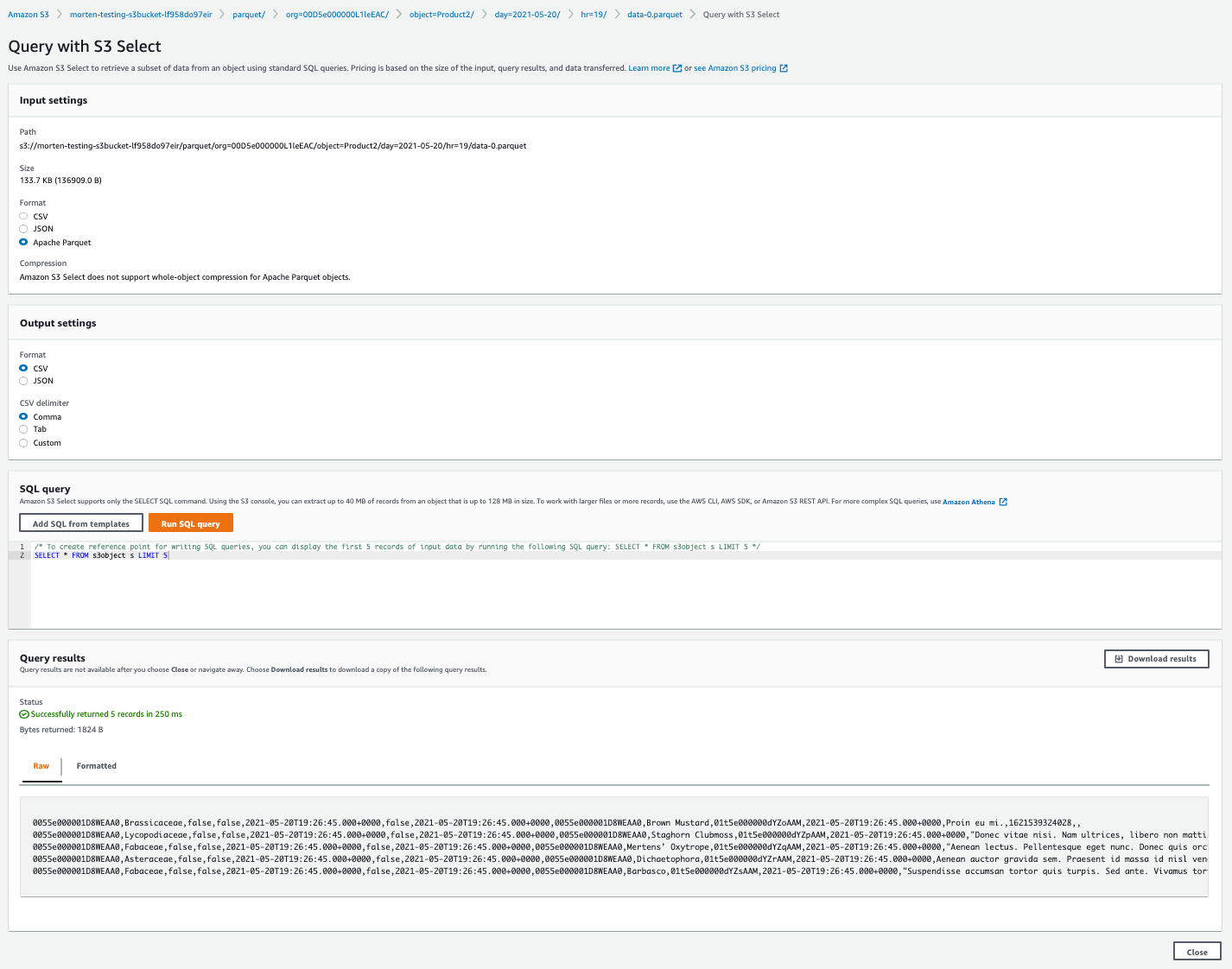
S3 Select is a recent addition to the AWS S3 feature set that allows you to issue SQL queries directly against objects stored in S3. Parquet is one of the formats supported by this feature. Here's how you use it:
- Log in to the AWS Console and navigate to S3
- Locate an hourly partition with data in it
- In the "Object Actions" menu, select "Query with S3 Select"
- On the next screen, make sure the input format is "Apache Parquet" and set output to "CSV"
- Run the default query to return the first 5 records from the file.
Useful to Know
Limits
Feature Limitations
The History Stream currently supports up to 100 enabled objects. If you need additional objects enabled, please contact your GRAX Account Manager.
The GRAX Parquet Format
History Stream data is written in Apache Parquet format. One of the advantages of Parquet vs other interchange formats like CSV, is that you can encode schema with the object data. It also supports excellent compression. Parquet is well supported by all major ETL, data storage and data processing platforms.
Salesforce Data Types vs Parquet Data Types
In version 1.0 of the History Stream all Salesforce field data types are treated as Strings in Parquet. We do this to allow the smoothest integration with ETL tooling like AWS Glue, knowing that most of our customers want to stage schemas to their preference once the data is on-boarded in the data lake or analytics warehouse.
GRAX Metadata Fields
In addition to the Salesforce object data embedded in the parquet files, GRAX adds the following metadata fields prefixed by grax__:
grax__addedParquet timestamp format indicated when the record was written to the GRAX Vault.grax__deletedParquet timestamp format indicated when the record was deleted from Salesforce.grax__deletesourceString indicating whether the record was deleted bygraxorsalesforce.
Dates are stored in Unix Timestamp format in milliseconds. The integer is the number of milliseconds since midnight on the first of January, 1970.
Converting timestamps to readable dates
You may need to do some conversion to turn UNIX timestamps into easily readable dates. Fortunately, this is quite simple to do. For example, in AWS Athena you can use the following conversion function to display the grax__added metadata field as a readable date:
select from_unixtime(grax__added / 1000) AS readableDate from mytableThis would yield dates in a format like this:
2021-05-10 22:23:52.000
Note that this is still in UTC
Managing Duplicates
A fundamental principle of the History Stream is that you get all the versions of all records that we have stored for enabled objects. Ultimately this feature is what enables you to accurately analyze how your data evolves over time. Because of this, some amount of duplicate records in the parquet extracts are inevitable and expected; your reports, queries etc. need to account for duplicates accordingly.
For example, the following Salesforce conditions cause a new version to be captured by GRAX while the LastModifiedDate and SystemModstamp fields remain unchanged between versions:
- Formula Fields: If you are backing up formula fields for a given object, and only the formula field value changed, GRAX captures a new version but the SystemModStamp/LastModifiedDate audit date field won't change.
- Schema Changes: When the schema changes (including changing default field values), GRAX captures a new version but the SysModStamp/LastModified audit date field won't change. This is because each version of a record is uniquely tied to its schema at the time of capture.
Additionally, here are some examples of GRAX behaviors that can also produce duplicate records - at least at the Salesforce data level:
- Full Backups: Running on-demand or periodic full backups for an object captures a new version for each included record, regardless of whether we already have a version in storage with the same LastModifiedDate or SystemModstamp.
- Archiving: As the first step of an archive process, GRAX captures a full backup of the current state of each included record. Even if the record did not change, this results in a duplicate version.
- Delete Tracking: GRAX performs periodic delete tracking. When we detect a deleted record, we add GRAX metadata to capture the time of the delete. Because this is purely GRAX metadata, the SysModStamp/LastModified fields won't change, but you get a new version with a timestamp value in
grax__deleted:
![]()
Managing duplicate record data: delete tracking.
Working with History Stream Data
Now that History Stream is turned on, you're ready to make use of your data in other systems. We've built this feature to support any type of data lake or analytics platform with minimal effort. Here are some examples of integrating with the most popular targets for History Stream data:
- Crawling History Stream data with AWS Glue
- Converting historical data to CSV with AWS Glue
- Loading data into AWS Redshift
- SQL queries on the History Stream with AWS Athena
- Reporting on archived data with Tableau CRM
- Visualizing historical data in Tableau Desktop/Online
- Analyzing historical data with AWS QuickSight
- Loading historical data into Microsoft Azure Synapse Analytics
Updated 9 days ago